Indexação é uma forma de otimização de consultas no seu banco de dados. Para aplicar a indexação, é necessário antes compreender um pouco mais a fundo do funcionamento de um banco de dados e como o index vai atuar.
Consultas
Os dados são armazenados em memória secundária(HDD, SSD). É importante notar que operações em memórias primárias(RAM) são sempre mais rápidas em comparação a memória secundária.
Em cenários onde se trabalha com grande quantidade de dados, consultas em disco são custosas e a latência é alta. Técnicas de otimização, como a indexação que iremos trabalhar, são os meios de garantir a eficiência da aplicação.
Buffer Pool
O buffer pool é um mecanismo do S.O que atua como um cache. Sempre que uma consulta é feita, internamente é verificado primeiramente o buffer, caso o dado seja encontrado a consulta é finalizada e nenhuma operação em disco é feita.
O buffer não é uma “bala de prata”. Seu tamanho é limitado e ele pode falhar. Isso significa que a latência da consulta pode, e provavelmente, irá continuar alta.
B-trees
É a estrutura de dados no qual os blocos de dados são salvos. B-trees foi criada especialmente para salvar dados em memórias secundárias, uma vez que fornece características otimizadas para tal.
B-trees e suas características, algoritmos de busca e inserção e outros detalhes devem ser abordados em um outro post devido a sua complexidade.
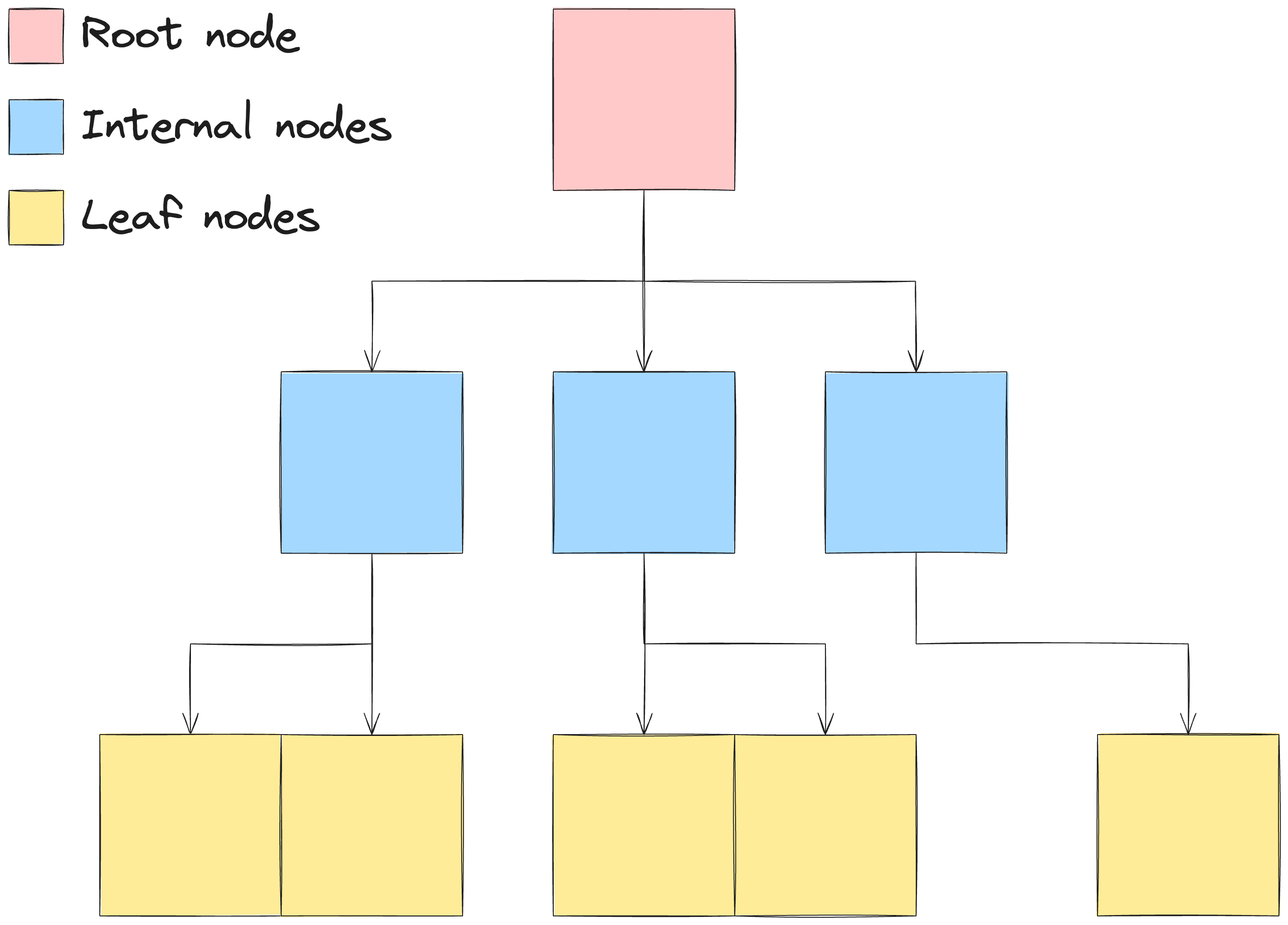
Uma observação é que nem todos os bancos implementam B-trees, porém é o mais utilizado em geral.
Tipos de acesso
Utilizando a palavra EXPLAIN no início de uma query, podemos observar alguns detalhes ao executar. Será possível identificar quantas rows foram percorridas e também identificar o tipo de acesso utilizado.
Quando uma consulta é feita, tipos de acesso são utilizados para acessar os dados. Vamos dividir esses tipos em quatro:
CONST e EQ_REF
É usado SOMENTE em casos onde o objetivo é encontrar um valor único. O algoritmo performa uma busca binária pela árvore.
Só é utilizado em dois casos: Primary key e Unique CONSTRAINT.
REF e RANGE
É usado em casos onde o objetivo é encontrar um intervalo de valores que satisfazem a consulta. É importante pois reduz a quantidade de colunas onde o algoritmo irá trabalhar para encontrar os intervalos.
O algoritmo primeiramente irá encontrar, na árvore, o “starting point” do intervalo que satisfaz aquela condição e todo o outro resto será ignorado. A partir do starting point, o algoritmo irá buscar os valores que satisfazem a condição.
INDEX
A consulta é iniciada a partir de uma folha e é feita a procura em todo o restante a partir daquela folha na árvore.
ALL
É o menos performático. O Algoritmo percorre toda a árvore para encontrar os valores que satisfazem a condição da consulta.
Prática - Parte 1
Considere a seguinte tabela, com algumas centenas de registros:
1 - Obter a soma do total em um determinado ano
A solução mais simples seria algo semelhante a isso:
EXPLAIN SELECT SUM(e.total)
FROM example e
WHERE YEAR(e.created_at) = 2020;
Essa query irá funcionar bem em cenários onde há poucos dados. Porém, em cenários onde há uma quantidade enorme de dados, essa consulta será lenta.
Como otimizar isso? A resposta é index.
2 - Adicionando Index
Adicionamos o index á coluna created_at:
ALTER TABLE example
ADD INDEX idx_created_at (created_at, total);
Quando executar a consulta novamente, você irá perceber que nada mudou. Por quê? Vamos entender o problema com ajuda do EXPLAIN.
3 - Debbugando
Acrescentando a palavra EXPLAIN no inicio da query, alguns novos campos serão exibidos:

Observando as colunas possible_keys e key, colunas que indicam o uso de index, estão como null. Isso significa que o index não está sendo usado. Observe também as colunas rows e type, elas indicam o tipo de acesso(access type, explicado acima) e a quantidade de rows percorridas pela consulta.
Por quê? O motivo é uso de FUNCTIONS, ou seja, você não pode usar index quando estiver utilizando functions. Vamos reescrever essa query:
EXPLAIN SELECT SUM(e.total)
FROM example e
WHERE created_at BETWEEN '2020-01-01' AND '2020-12-31';
Ao executar novamente, percebemos o uso correto do index:

4 - Considerações sobre a coluna total
Observando o passo 2, acrescentamos a coluna total ao index além da coluna created_at. Por quê? E se “total” não estivesse no index?
Vamos observar dois detalhes sobre index:
- O index é uma estrutura de dados carregada em memória primária(RAM). Por isso a consulta é mais rapida.
- O index armazena apenas as colunas específicadas.
Se a coluna total não estivesse no index, a query teria que carregar esse dado da coluna total a partir do disco.
Isso significa uma latência MAIOR do que trabalhar sem o index, pois a consulta teria que fazer X operações I/O, onde X é igual ao número de resultados que satisfazem a condição da consulta.
Se você não se atentar a esses detalhes, você vai tornar a performance da sua aplicação pior.
Prática - Parte 2
É comum cenários onde consultas vão utilizar mais de uma coluna e também mais de uma condição. Vamos trabalhar nisso.
1 - Filtrando por UserId
Imagine um cenário agora, onde será necessário filtrar também por usuário. A query seria algo semelhante a isso:
EXPLAIN SELECT SUM(e.total)
FROM example e
WHERE created_at BETWEEN '2020-01-01' AND '2020-12-31'
AND user_id = 136;
Ao debbugar, você vai perceber que, o tipo de acesso é um range, mas por algum motivo a coluna rows indica um número alto ainda. Isso é um problema!

2 - Adicionando UserId ao index
Vamos alterar o index:
ALTER TABLE example
DROP INDEX idx_created_at;
ALTER TABLE example
ADD INDEX idx_created_at (created_at, total, user_id);
3 - Debbugando
Utilizando o explain, você percebe que nada mudou.

O que aconteceu? Vai ser necessário entender que a ordem das colunas do index importa!
4 - Seletividade do Index
Quando se trata de múltiplas colunas, o index vai ser sempre mais seletivo da Esquerda para a Direita. Isso Significa que, na execução dessa query, o index irá tentar satisfazer a primeira coluna(created_at) com a condição BETWEEN.
O problema é: Podem existir centenas de valores que satisfazem essa condição, logo todos serão carregados no index e serão percorridos pelo algoritmo, que irá fazer as demais verificações da query(user_id = 136).
5 - Use a seletividade a seu favor!
Vamos alterar o index para usar como seletividade a coluna user_id.
ALTER TABLE example
DROP INDEX idx_created_at;
ALTER TABLE example
ADD INDEX idx_created_at (user_id, created_at, total);
Ao executar a query, percebemos uma melhora significativa.

Apenas uma coluna foi percorrida. O que aconteceu? É simples: É mais provável que tenha menos resultados com user_id = 136, logo menos dados serão carregados no index e portanto será mais peformático!
6 - Nem tudo são flores Se você realizar essa mesma query, sem a condição do user_id, você vai perceber que a performance ficou pior.

Isso infelizmente é algo que apenas o desenvolvedor, dentro do contexto da aplicação, vai saber a melhor forma de aplicar o index.
Considerações Finais
Podemos tirar algumas conclusões:
- Não existe uma “bala de prata”. A solução vai ter suas consequências positivas e negativas.
- Somente o desenvolvedor, que entende o contexto do uso das queries na aplicação, vai conseguir utilizar o index da melhor forma.
Créditos
Esse artigo foi baseado na palestra de Kai Sassnowski.